Problem description:
K10 backupaction for longhorn volumes fails with the error message too many snapshots created.
Explanation:
When integrating with CSI based volumes, K10 uses volumesnapshot resources to provision a snapshot during the backup action.
In case of longhorn, as soon as the volumesnapshot and its corresponding volumesnapshotcontent resource is created by the snapshot-controller, Longhorn creates a snapshots.longhorn.io resource and synchronises it to create a backend longhorn snapshot.
And based on retention, K10 deletes this volumesnapshotcontent resource to remove the snapshot.
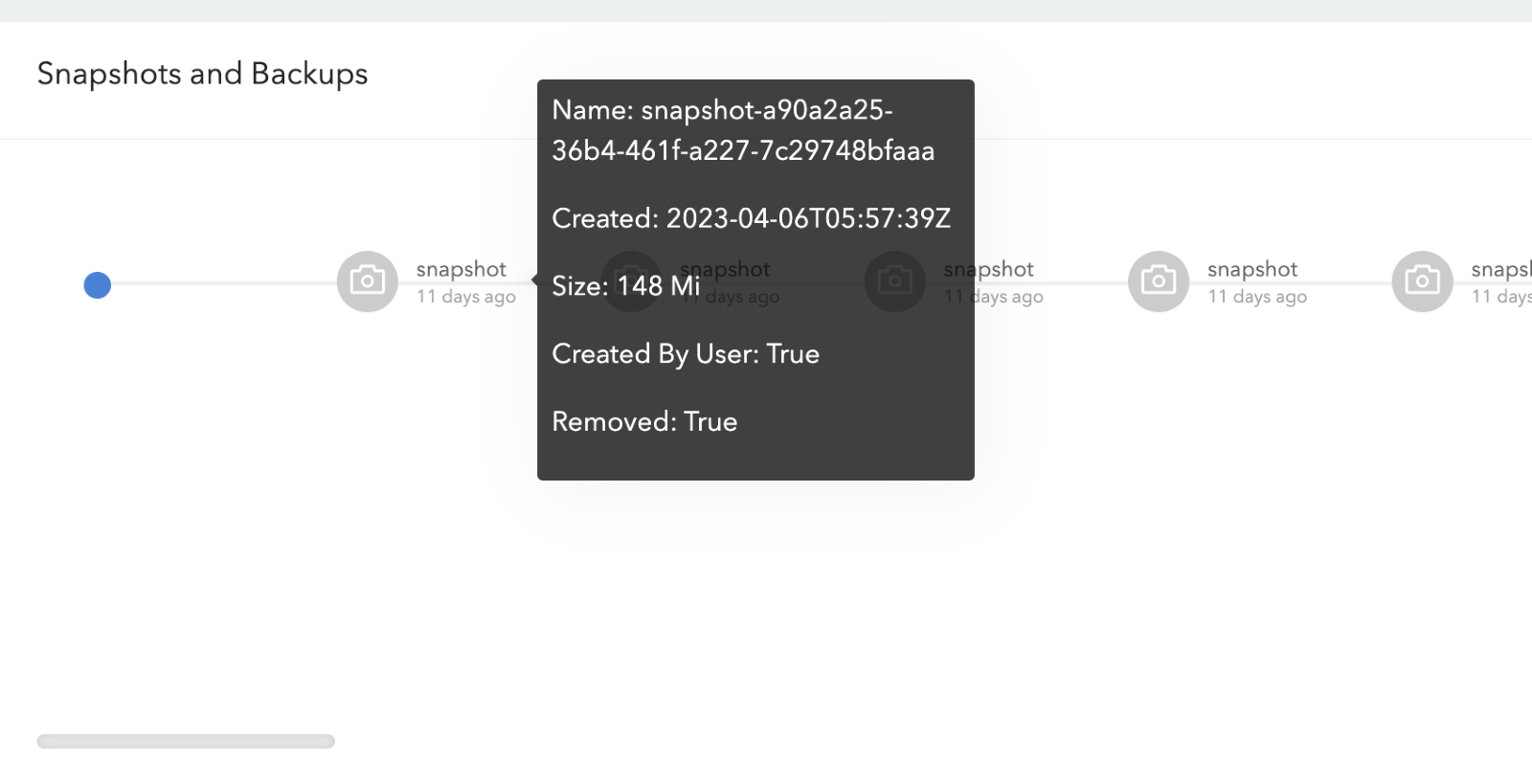
However, Longhorn does not directly remove the snapshots.longhorn.io resource that it creates. It just marks the snapshot as removed but does not purge it.
In due course, this builds up the number of snapshots per volume when the backup runs for this volume and starts failing when reaches the limit of 254 snapshots per longhorn volume.
Below is the sample snapshot count for a sample application that was set to retain 8 snapshots in K10.
#PVC in one sample namespace
❯ kubectl get pvc -n postgresql
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-postgres-postgresql-0 Bound pvc-fafda05d-314e-420f-bf37-d7365b31ea1c 8Gi RWO longhorn 24h
#count of volumesnapshot resource
❯ kubectl get volumesnapshot -n postgresql --no-headers|wc -l
8
#Count of longhorn snapshot CRs
❯ kubectl get snapshots.longhorn.io -n longhorn-system |grep pvc-fafda05d-314e-420f-bf37-d7365b31ea1c |wc -l
85
Below is the screenshot from Longhorn UI showing hidden snapshots which are marked as removed but not purged.
Resolution:
Currently, Longhorn does not purge the removed snapshots automatically when the volumesnapshot/volumesnapshotcontent resources are deleted from the k8s cluster.
Longhorn introduced a new type of recurring job called snapshot-cleanup starting from its version 1.4.1 to purge removed snapshots and system snapshots.
This can be used to purge the removed snapshots from longhorn backend.
It can be created both from the longhorn UI or the kubectl API
From the Longhorn UI, RecurringJob -> create RecurringJob
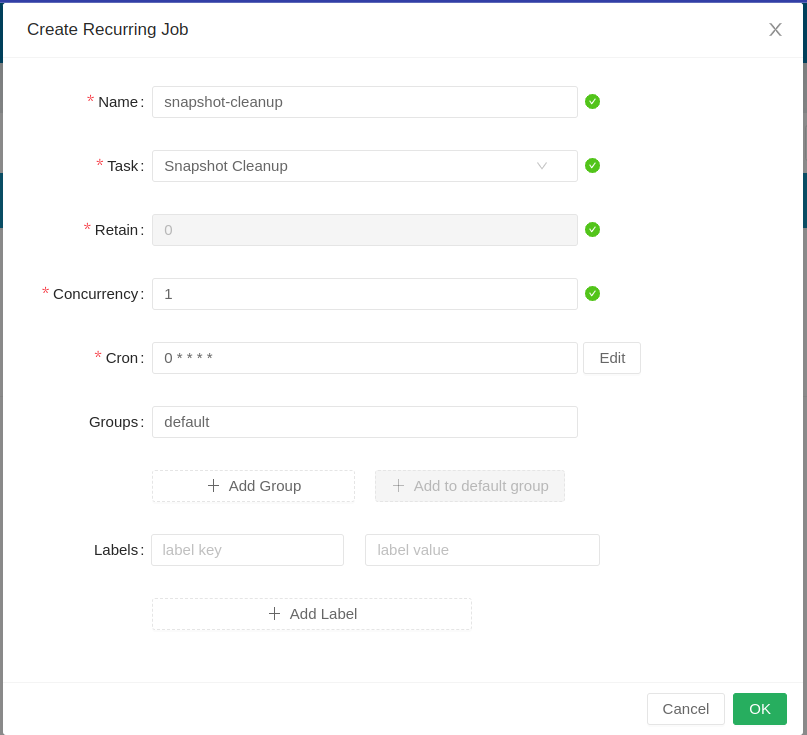
select Group if default group needs to be added (Having default in groups will automatically schedule this recurring job to any volume with no recurring job).
Use the below kubectl command to create the recurringJob resource from the CLI.
cat << EOF | kubectl create –f -
apiVersion: longhorn.io/v1beta2
kind: RecurringJob
metadata:
name: snapshot-cleanup
namespace: longhorn-system
spec:
concurrency: 1
cron: 0 * * * *
groups:
- default
labels: {}
name: snapshot-cleanup
retain: 0
task: snapshot-cleanup
The recurring Job creates a K8s cronjob resource which in turn runs snapshot-cleanup pod as per the cron expression specified during the job creation.
Below is the log from the snapshot-cleanup pod that ran after the creation of the recurring job.
❯ kubectl logs snapshot-cleanup-28069140-c8cm5 -n longhorn-system
time="2023-05-15T11:00:00Z" level=debug msg="Setting allow-recurring-job-while-volume-detached is false"
time="2023-05-15T11:00:00Z" level=debug msg="Get volumes from label recurring-job.longhorn.io/snapshot-cleanup=enabled"
time="2023-05-15T11:00:00Z" level=debug msg="Get volumes from label recurring-job-group.longhorn.io/default=enabled"
time="2023-05-15T11:00:00Z" level=info msg="Found 1 volumes with recurring job snapshot-cleanup"
time="2023-05-15T11:00:00Z" level=info msg="Creating job" concurrent=1 groups=default job=snapshot-cleanup labels="{\"RecurringJob\":\"snapshot-cleanup\"}" retain=0 task=snapshot-cleanup volume=pvc-84d3d7d0-3abc-427c-a959-5ccc7da912a5
time="2023-05-15T11:00:01Z" level=info msg="job starts running" labels="map[RecurringJob:snapshot-cleanup]" namespace=longhorn-system retain=0 snapshotName=snapshot-90135f33-93ce-4de4-829b-4dd01db2d827 task=snapshot-cleanup volumeName=pvc-84d3d7d0-3abc-427c-a959-5ccc7da912a5
time="2023-05-15T11:00:01Z" level=info msg="Running recurring snapshot for volume pvc-84d3d7d0-3abc-427c-a959-5ccc7da912a5" labels="map[RecurringJob:snapshot-cleanup]" namespace=longhorn-system retain=0 snapshotName=snapshot-90135f33-93ce-4de4-829b-4dd01db2d827 task=snapshot-cleanup volumeName=pvc-84d3d7d0-3abc-427c-a959-5ccc7da912a5
time="2023-05-15T11:00:01Z" level=debug msg="Purged snapshots" labels="map[RecurringJob:snapshot-cleanup]" namespace=longhorn-system retain=0 snapshotName=snapshot-90135f33-93ce-4de4-829b-4dd01db2d827 task=snapshot-cleanup volume=pvc-84d3d7d0-3abc-427c-a959-5ccc7da912a5 volumeName=pvc-84d3d7d0-3abc-427c-a959-5ccc7da912a5
time="2023-05-15T11:00:01Z" level=info msg="Finished recurring snapshot" labels="map[RecurringJob:snapshot-cleanup]" namespace=longhorn-system retain=0 snapshotName=snapshot-90135f33-93ce-4de4-829b-4dd01db2d827 task=snapshot-cleanup volumeName=pvc-84d3d7d0-3abc-427c-a959-5ccc7da912a5
time="2023-05-15T11:00:01Z" level=info msg="Created job" concurrent=1 groups=default job=snapshot-cleanup labels="{\"RecurringJob\":\"snapshot-cleanup\"}" retain=0 task=snapshot-cleanup volume=pvc-84d3d7d0-3abc-427c-a959-5ccc7da912a5
Please refer to below longhorn documentation to read more about recurringJobs.
- Recurring jobs (https://longhorn.io/docs/1.4.2/snapshots-and-backups/scheduling-backups-and-snapshots/)
- Set up Recurring Jobs to be the Default group (https://longhorn.io/docs/1.4.2/snapshots-and-backups/scheduling-backups-and-snapshots/#set-up-recurring-jobs-to-be-the-default)
- Assign recurringJob to volumes by kubectl label command (https://longhorn.io/docs/1.4.2/snapshots-and-backups/scheduling-backups-and-snapshots/#recurring-job-assignment-using-the-kubectl-label-command)
- Assign recurringJobs to new volumes using storageClass (https://longhorn.io/docs/1.4.2/snapshots-and-backups/scheduling-backups-and-snapshots/#recurring-jobs-assignment-using-a-storageclass)